爬蟲其實是一個入門簡單,但是後面學習曲線會越來越陡峭的一門實用技術
別的網路上教學都會先闡述一些基礎知識 , 不過我覺得這樣學起來太枯燥乏味 , 所以我們直接進入實戰主題 !
爬蟲眼中的世界
我們透過瀏覽器所看到的網頁呈現,跟爬蟲所看到的並不同,他們看的是網頁原始碼。
舉個例子,就像我們走進便利超商,拿起架上的三明治,我們會看到肉片、蔬菜以及吐司,非常直觀地出現在眼前;但是爬蟲看得比較像是標籤上的說明,例如鈉含量、卡路里等等抽象純文字的說明。
打開任一網頁,按右鍵,選擇檢查網頁原始碼,再想想我剛剛的舉例,有個印象即可。
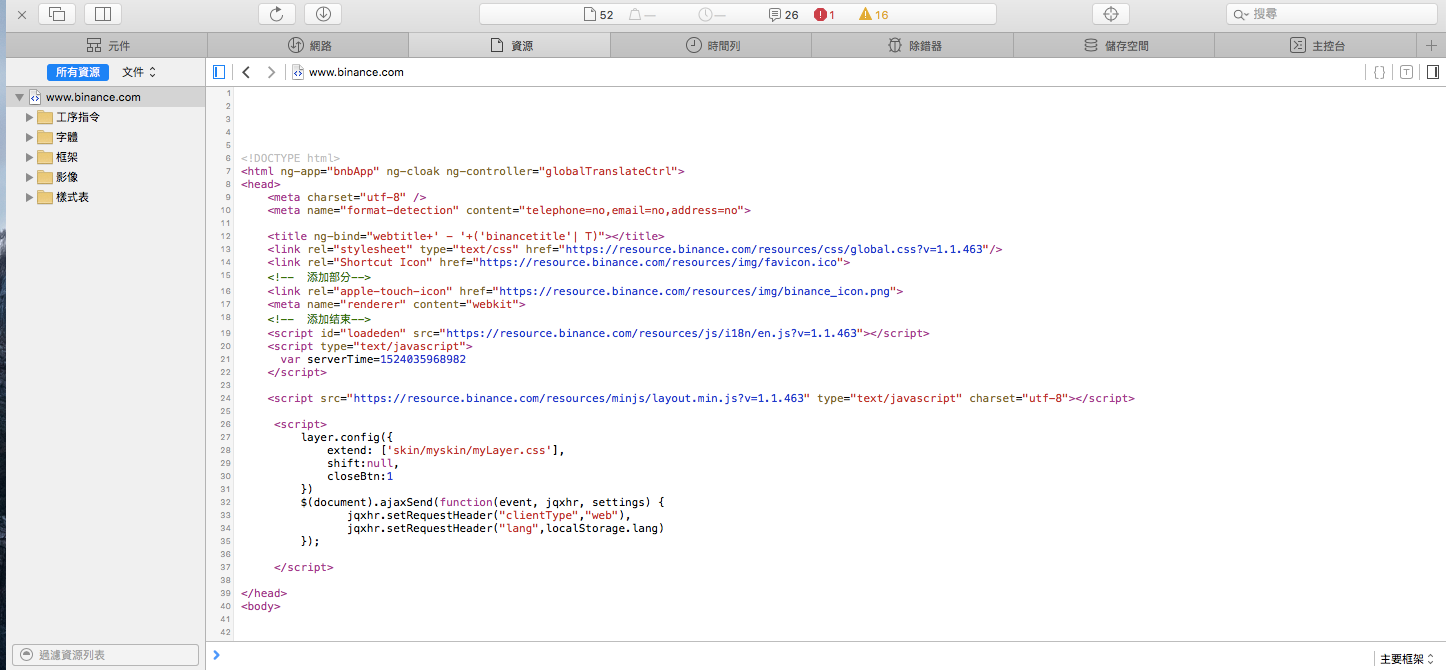
JavaScript 渲染後的畫布
但並不是所有的網頁內容,在右鍵的檢查網頁原始碼中都會看到。
網頁是由 HTML、CSS、JavaScript 所組成。
沒概念也不用緊張,想像你眼前有個漂亮的玻璃展示櫃,裡面按照一定距離排列了許多公仔,每個公仔各自被展示燈所照著。而櫃子旁的牆壁上,有三個開關,旁邊分別寫著HTML、CSS、JavaScript,JavaScript就像電燈開關一樣,打開它公仔就變亮關起來,公仔就消失不見。
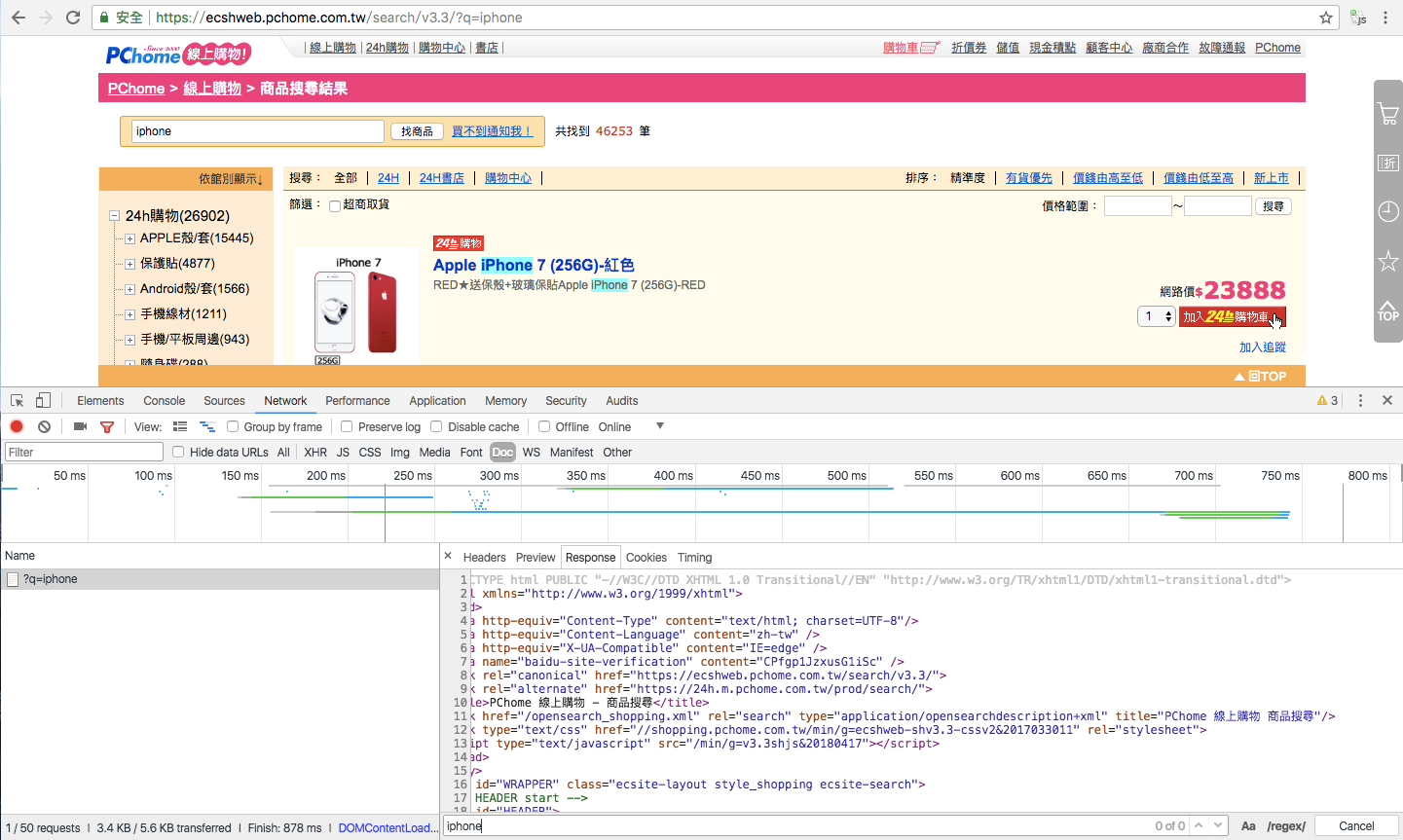
以PChome線上購物為例
https://ecshweb.pchome.com.tw/search/v3.3/?q=iphone
以PChome線上購物為例,搜尋iPhone後的商品列表,每個標題都有「iPhone」關鍵字;但是如果以爬蟲的視角,在網頁原始碼中,用搜尋是找不到「iPhnoe」關鍵字的。
原因在於該網頁的完整呈現,需要開啟開關。
也就是他們用上了js渲染技術 !
所以我們要考慮所要抓取的內容是否使用了JavaScript渲染,來決定對應的方式。
使用套件requests,也是獲取網頁原始碼最常使用的套路:
import requests
res = requests.get('target_url')
print(res.text)
帶入網址
import requests
res = requests.get('http://pala.tw/js-example/')
print(res.text)
其實就像是眼前的空白牆壁有一堆塗鴉,但是有些地方筆畫不連貫消失了,必須戴上特製的眼鏡才看得到完整的內容。
需要的套件
使用 pip 來安裝套件,
requests 發送接收 HTTP 請求及回應
官方標語: HTTP for Humans,這才是真正給人用的介面啊,建議不要直接使用內建的 urllib 模組!
beautifulsoup 用來分析與抓取 html 中的元素
簡單好用,沒有嚴格要求解析速度的話是個很好的選擇。
pip install requests
pip install beautifulsoup4
(選用) lxml 用來解析 html/xml
簡單好用(?),解析速度快多了!不過想要直接透過 lxml 解需要先熟悉 xpath 語法,其實也挺容易學的~
可在這邊找到好心人為 Windows 預編譯好的 wheel (Unofficial pre-compiled lxml)
p.s. 最近作者也提供編譯好的 Windows 版本在 PyPi 上了,各系統應該都能用 pip 安裝了~
# install through pip
pip install lxml
# if you have conda, congrats!
conda install lxml
# if on debain/ubuntu, you may install binary directly...
sudo apt-get install python3-lxml
# if on windows, you may install from lxml wheel
pip install lxml-3.8.0-cp35-cp35m-win_amd64.whl
快捷鍵
[ OS ]
- option+command+F (Find All Replace ALl)
- command + F (Find)
- option + command + I (開發人員工具)
[ windows ]
- Alt + F3 (Find All Replace ALl)
- control + F
- shift+ctrl+I (開發人員工具)